全球第一个!深圳十方融海科技有限公司率先开发出免费使用开源可商业化中文大语言模型
| 后台-插件-广告管理-内容页头部广告(手机) |
在人工智能领域,大语言模型正以前所未有的速度发展,已经成为众多企业、研究机构和个人开发者的新宠。十方融海作为以数字科技创新为展新引擎的数字职业在线教育科技企业,也将AI大语言模型作为公司科研创新主要...
在人工智能领域,大语言模型正以前所未有的速度发展,已经成为众多企业、研究机构和个人开发者的新宠。十方融海作为以数字科技创新为展新引擎的数字职业在线教育科技企业,也将AI大语言模型作为公司科研创新主要发力方向之一,技术团队一直刻苦钻研,致力于提供开放、免费获取、公开下载、可离线部署的,具备真正认知能力和顿悟能力的大语言模型,并在多语言模型训练方面积攒了丰富的经验。
近日,十方融海集团旗下威科软件宣布联合团队成员包括业界开源爱好者和学术研究者的OpenBuddy团队,领先业界推出了国内首个基于Falcon架构、可商用的中文跨语言模型——OpenBuddy-Falcon-7B,这也是全球第一个可免费使用开源的中文大语言模型,适用于大多数商业应用场景需求,且家用显卡也能轻松运行,为个人和企业提供更便捷、更全面的大语言模型智能化应用。
今年 5 月,Tii 研究机构发布了 Falcon 模型,使用 Apache 2.0 的可商用开源协议,Falcon 模型不仅在协议和数据集方面更加开放,还采用了最新的 Flash Attention 等技术,展现出了惊人的性能和内容质量。Falcon 模型一经发布,便荣登 Huggingface Open LLM Leaderboard 的首位,成为最新的 SOTA 开源大语言模型。
十方融海在Falcon模型推出之初,便对其产生了浓厚的兴趣。十方融海技术团队深知,现有的 SOTA 开源语言模型,包括 LLaMA 和 Falcon,都存在“跨语言支持能力薄弱”这一问题。这些模型主要以英语、法语等印欧语系为基础,并且缺乏跨语言对话场景的深度优化。因此,它们在理解中文等非印欧语系语言方面存在困难,更无法进行有意义的对话。
对此,为了给个人和企业提供更便捷、更全面的大语言模型智能化应用,经过不懈的研究和试错,十方融海旗下威科软件联合OpenBuddy 团队成功地掌握了 Falcon 模型的训练诀窍,推出了全球首个基于 Falcon 架构、开放可商用的中文跨语言大模型——OpenBuddy-Falcon-7B。
相较于原始Falcon模型,OpenBuddy-Falcon-7B 在跨语言能力方面更具优势,支持包括中文、日语、韩语、英语、法语、德语等多种语言。
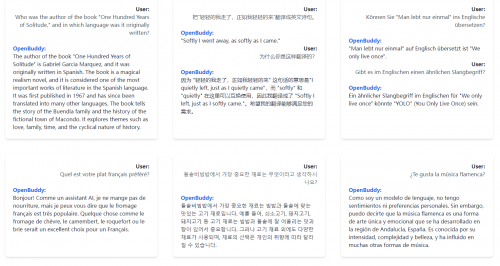
通过采用新颖的跨语言学习技术与深度优化对话场景,大幅提高了模型对跨语言知识的理解能力和融合能力,模型可以实现在各种语言之间进行自由、流畅的对话,并能在多种语言直接切换,完成翻译等需要跨语言能力的任务。
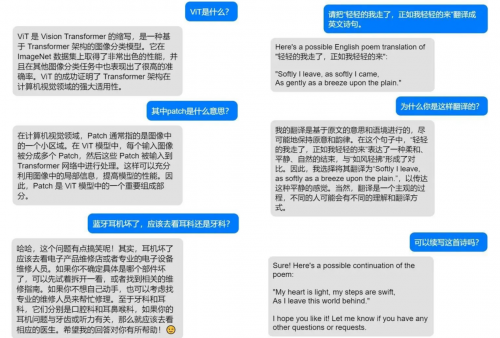
此外,模型具备插件使用能力,能分析用户的意图,自动选取并调用插件。例如,调用Stable Diffusion 开源模型画图,调用内置的搜索引擎搜索资料等等;模型更是能够深度理解用户的需求,可以完成问答、写作、模仿、创作等多种任务,还可以完成“画一个车水马龙的街道”,“画一个丑小鸭长大后变成的动物”等复杂指令。

这并非十方融海首次推出中文大语言模型。事实上,十方融海技术团队已经在多语言模型训练方面积累了丰富的经验,早在falcon模型推出之前,十方融海联合OpenBuddy 团队就曾在 LLaMA 的 7B、13B、30B 模型上进行了反复迭代和调优,研发出了OpenBuddy-LLaMA 系列开源模型。这些模型在中文、日语、韩语等多种语言上具备优秀的问题理解和回答能力,可以利用英文论文、代码等资料学习到的知识,为中文问题提供专业的回答和见解。
作为跨语言模型,OpenBuddy-LLaMA 系列在中文、日语、韩语等多种语言上具备优秀的问题理解和回答能力,也吸引了全世界众多开放模型爱好者的关注,llama.cpp、Langport、FastChat 等开源项目均实现了OpenBuddy-LLaMA 系列模型的集成,并在社区中获得了广泛的应用。
十方融海技术团队负责人表示,OpenBuddy-Falcon-7B 的发布,标志着一个崭新的时代的到来。在这个时代里,跨语言的大模型不再是科技巨头的专利,而是开放、可商用的资源,能为全球的开发者、企业和研究者提供强大的支持。相信 OpenBuddy-Falcon-7B 的发布,将对跨语言 AI 领域的发展产生深远的影响,未来也有望见证更多基于 OpenBuddy-Falcon-7B 的创新应用和突破性技术问世,共同推动人工智能领域的繁荣发展。
值得一提的是,目前除了 7B(70亿)参数的模型以外,OpenBuddy 团队还在训练以13B(130亿)、40B(400亿)为训练参数的OpenBuddy-LLaMA-13B、OpenBuddy-Falcon-40B等百亿规模的大语言模型,在大规模语言模型的积累训练上同样有着丰富的见解和经验。
在十方融海董事长黄冠的带领下,十方技术团队在AI大语言模型上将持续取得创新和突破,在更好满足大众平等使用AI技术需求的同时,也让十方在新的AI大浪潮下走在前列。未来,十方将始终保持求是创新、拥抱变化的态度,为社会、为用户创造出更大的价值。
| 后台-插件-广告管理-内容页尾部广告(手机) |